options(repos = c(CRAN = "https://cran.rstudio.com/"))
install.packages("tidyverse", quiet= TRUE)package 'tidyverse' successfully unpacked and MD5 sums checkedConstituye un conjunto de procedimientos y estrategias dirigidos a los datos en su estado crudo, con el propósito de transformarlos en una estructura apropiada y funcional para su posterior análisis.
Identifica y abordar los valores faltantes en un conjunto de datos. Los valores faltantes pueden surgir por diversas razones, como errores de recopilación de datos o fallos en la medición.
options(repos = c(CRAN = "https://cran.rstudio.com/"))
install.packages("tidyverse", quiet= TRUE)package 'tidyverse' successfully unpacked and MD5 sums checkedCargamos la libreria
library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsCargamos el conjunto de datos
datos_csv_2 <- read.csv("ventas-por-factura.csv", header = TRUE, sep = ",")
head(datos_csv_2,5) N..de.factura Fecha.de.factura ID.Cliente País Cantidad Monto
1 548370 3/30/2021 16:14:00 15528 United Kingdom 123 229,33
2 575767 11/11/2021 11:11:00 17348 United Kingdom 163 209,73
3 C570727 10/12/2021 11:32:00 12471 Germany -1 -1,45
4 549106 4/6/2021 12:08:00 17045 United Kingdom 1 39,95
5 573112 10/27/2021 15:33:00 16416 United Kingdom 357 344,83Muestra la cantidad de valores faltantes por variable
colSums(is.na(datos_csv_2)) N..de.factura Fecha.de.factura ID.Cliente País
0 0 3724 0
Cantidad Monto
0 0 Eliminar filas con valores faltantes
datos_eliminados <- na.omit(datos_csv_2)Creamos un boxplot e identificamos outliers
boxplot(datos_csv_2$Cantidad)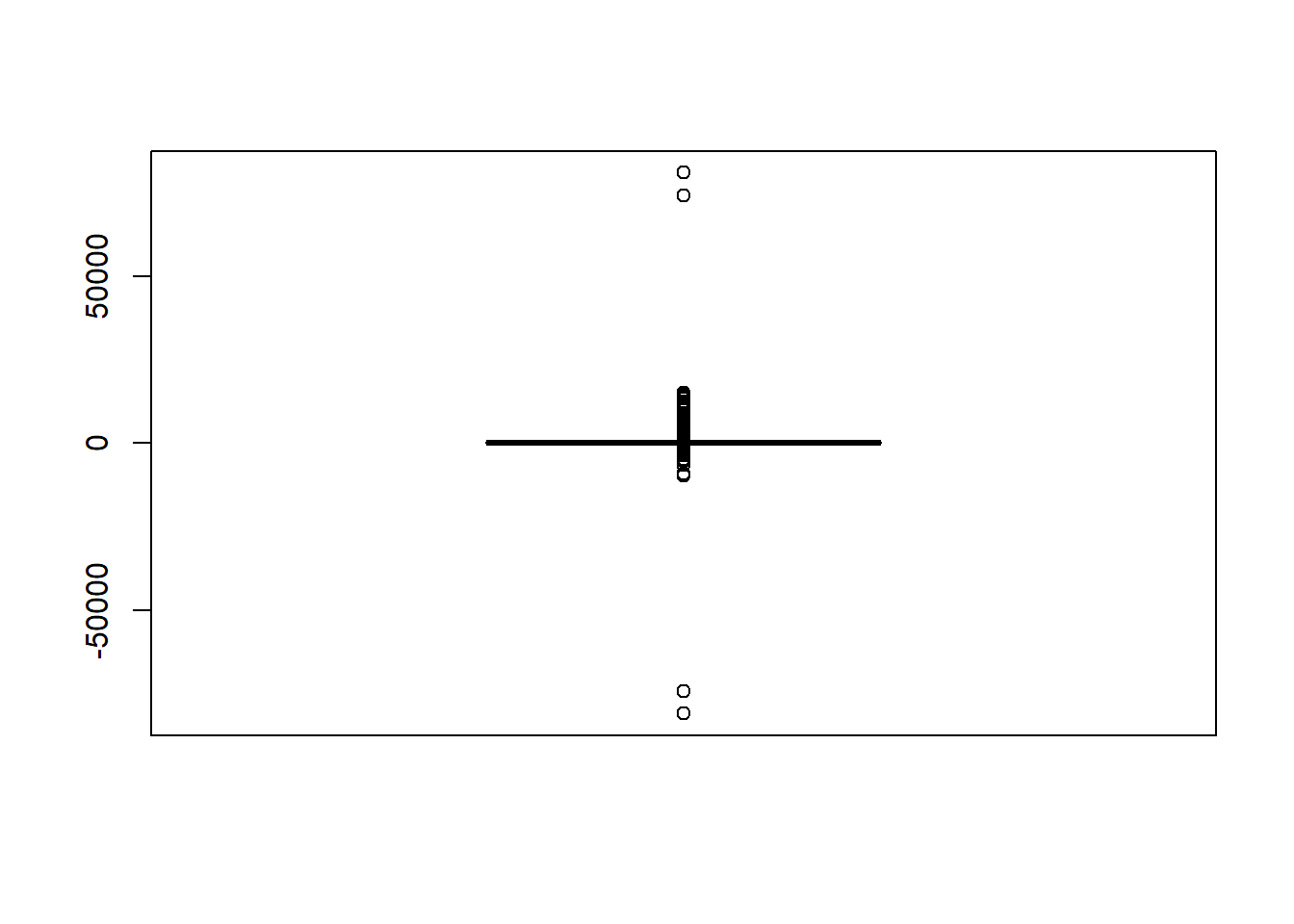
Instalar y cargar el paquete outliers
install.packages("outliers", quiet = TRUE)package 'outliers' successfully unpacked and MD5 sums checkedlibrary(outliers)outliers <- boxplot(datos_csv_2$Cantidad, plot = FALSE)$out
head(outliers,10) [1] 1484 1060 1644 -1200 938 -2344 1135 -1082 711 1600datos_csv <- read.csv("netflix_revenue_updated.csv",
header=TRUE,sep=",")Creación de nuevas variables
# Crear una nueva variable basada en operaciones con columnas existentes
datos_csv<- datos_csv %>%
mutate(columna_normalizada = (Global.Revenue - min(Global.Revenue)) / (max(Global.Revenue) - min(Global.Revenue)))
head(datos_csv,5) Date Global.Revenue UCAN.Streaming.Revenue EMEA.Streaming.Revenue
1 31-03-2019 4520992000 2256851000 1233379000
2 30-06-2019 4923116000 2501199000 1319087000
3 30-09-2019 5244905000 2621250000 1428040000
4 31-12-2019 5467434000 2671908000 1562561000
5 31-03-2020 5767691000 2702776000 1723474000
LATM.Streaming.Revenue APAC.Streaming.Revenue UCAN.Members EMEA..Members
1 630472000 319602000 66633000 42542000
2 677136000 349494000 66501000 44229000
3 741434000 382304000 67114000 47355000
4 746392000 418121000 67662000 51778000
5 793453000 483660000 69969000 58734000
LATM.Members APAC.Members UCAN.ARPU EMEA.ARPU LATM..ARPU APAC..ARPU
1 27547000 12141000 11.45 10.23 7.84 9.37
2 27890000 12942000 12.52 10.13 8.14 9.29
3 29380000 14485000 13.08 10.40 8.63 9.29
4 31417000 16233000 13.22 10.51 8.18 9.07
5 34318000 19835000 13.09 10.40 8.05 8.94
Netflix.Streaming.Memberships columna_normalizada
1 148863000 0.0000000
2 151562000 0.1104581
3 158334000 0.1988493
4 167090000 0.2599750
5 182856000 0.3424517